Le 15 novembre 2010, le projet GITAN a été présenté dans le cadre du colloque annuel de PROMPT. Voir la présentation.
Nouvelles
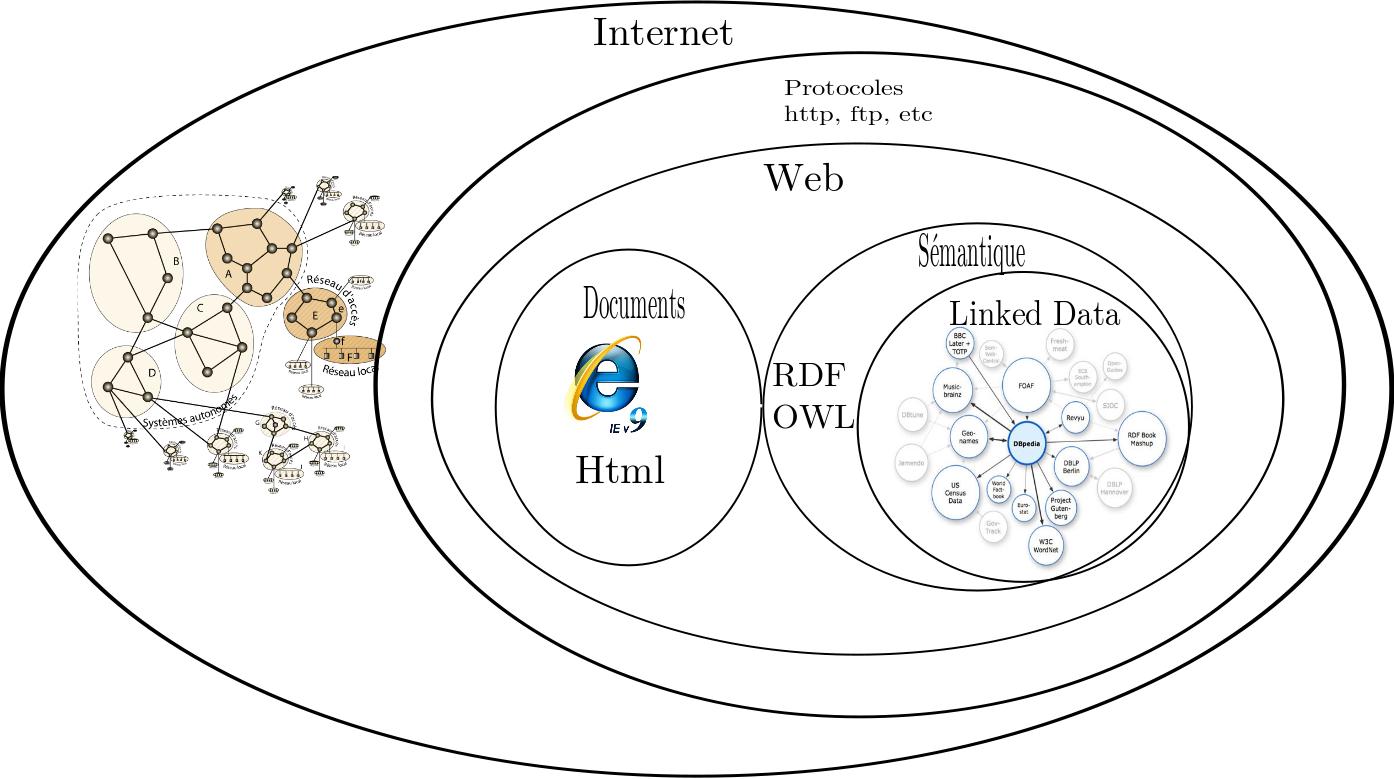
Gitan au colloque de PROMPTLes premiers pas de Gitan dans le Web sémantique !Pour assurer la représentation d'un contenu textuel sous forme d'animation, il est nécessaire d'identifier clairement l'identité des mot contenus dans ce texte afin de le mettre en relation avec l'objet graphique ou l'action qui lui correspond. L'utilisation des ressources du Web Sémantique pour assurer cette identification est l'une des voies de recherche des chercheurs du projet Gitan. Les premiers résultats sont présentés au cours d'une série de deux séminaires. Le web sémantique est une vision de l'internet documentaire dont les contenus ne seraient plus seulement des pages mais aussi des connaissances structurées et normalisées. Le réseau LinkedData est la manifestation la plus aboutie de ce web des données. Ce réseau offre dès aujourd'hui un accès libre à plus de 20 milliards d'informations sémantiques élémentaires, organisées en prédicats logiques inter-connectés, les triplets RDF. La croissance de ce réseau est forte et l'on voit régulièrement apparaître de nouvelles masses de données produites d'après une multitude de source (gouvernements, entreprises, milieux académiques). Le défi posé aujourd'hui par LinkedData est celui de son utilisation concrète.
Les recherches en Traitement Automatique de la Langue (TAL) menées par l'équipe du projet Gitan à l'École Polytechnique ont permis de mettre au point un système original d'identification de l'identité de mots contenus dans un texte en utilisant les ressources du Web sémantique. Ce dispositif est présenté lors de deux séminaires dont voici le résumé. Titre du Séminaire : Annotation automatique de texte avec le web sémantique et le réseau LinkedData (Diapositives en téléchargement ici) Durant cette présentation, nous décrirons un schéma original de mise en relation automatique d'entités nommées (un nom de personne, d'entreprise, de lieu, de produit) contenues dans un texte, avec leur représentation sur le réseau LinkedData. Après avoir présenté les caractéristiques du réseau LinkedData, nous rappellerons brièvement la problématique de l'annotation et de l'étiquetage de texte. Puis nous décrirons les algorithmes et les méthodes que nous avons élaborés pour mettre en relation un concept contenu dans un texte ouvert, avec sa représentation sémantique standardisée sur le réseau LinkedData. Nous présenterons notamment l'interface de liaison LDI (Linked Data Interface) que nous avons développée pour mettre au point un étiqueteur de texte original, compatible avec le web sémantique. Après avoir évalué les performance du système, nous conclurons cette présentation en mettant en perspective l'insertion de ce dispositif d'étiquetage sémantique dans le module de traitement de la langue du système de passage du texte vers l'animation Gitan. Dates du séminaire :
Première Rencontre ontologique de MontréalLa première rencontre ontologique de Montréal a eu lieu le mercredi 25 novembre 2009, à l'École polytechnique de Montréal. Nous débutons un projet de recherche concernant l'appariement de textes et de scènes d'animation. Le colloque se voulait un moyen d'établir un dialogue avec différents experts du domaine, à propos de ces questions fondamentales :
|
|
|