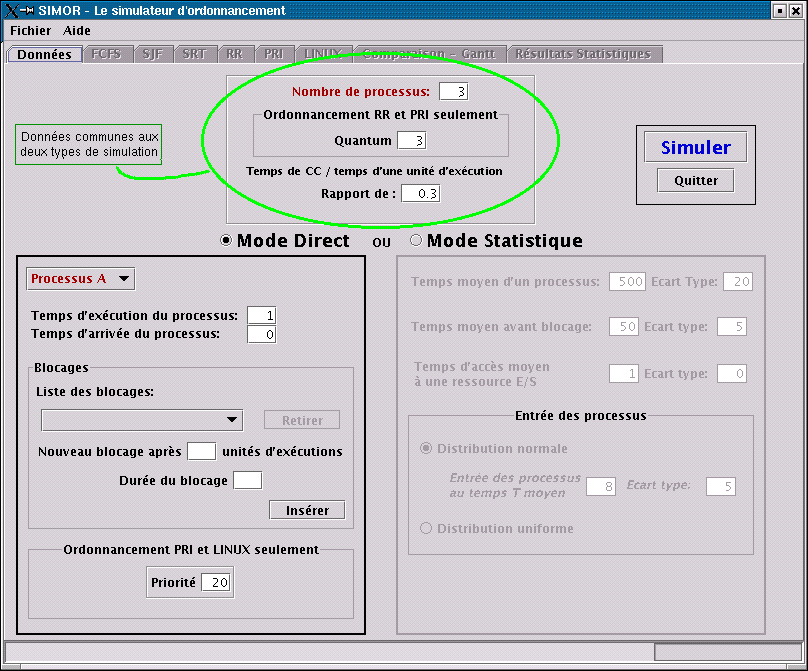
Peu importe le type de simulation (en mode direct ou en mode statistique), trois données sont nécessaires :
À toute personne ayant certaines notions de bases sur les modes d'ordonnancement d'un systèmes d'exploitation, désirant visualiser certaines situations particulières ou mesurer l'efficacité de diverses méthodes, vis-à-vis diverses situations. Ce logiciel vise plus directement les étudiants du cours INF3600 - Systèmes d'exploitation qui pourront grâce à ce simulateur générer des cas précis qui aideront à clarifier la matière théorique du cours, en plus de permettre de voir les grandes différences d'efficacité des divers modes d'ordonnancement théoriques.
Lorsque le simulateur est lancé, des données par défaut sont présentes dans les divers espaces de l'onglet Données. C'est dans ce même onglet où toutes les informations utiles à la simulation seront entrées. Les autres onglets, inaccessibles au départ, contiendront les résultats.
Deux modes de simulation sont offerts et certains champs de données
sont communs aux deux simulateurs.
Commençons par regarder les données communes :
Peu importe le type de simulation (en mode direct ou en mode
statistique), trois données sont nécessaires :
Nombre de processus : ce nombre doit varier entre 1 et 26 pour
le mode direct, et entre 1 et 150 pour le mode statistique. Cette
quantité représente le nombre de processus qu'on désire inclure dans la
simulation.
Quantum : le quantum est utilisé pour la simulation Round
Robin et à priorités pures uniquement. Pour les autres types
d'ordonnancement il est simplement ignoré. Le quantum représente le
nombre maximal d'unité de temps alloué à un processus qui s'exécute.
Rapport de temps de Changement de Contexte sur le temps d'une
unité d'exécution : puisque les temps de changement de contexte sont
des temps relatifs, surtout par rapport à une unité d'exécution, ce
champ est paramétrable. Il sera utilisé lors du calcul du temps moyen de
séjour avec CC.
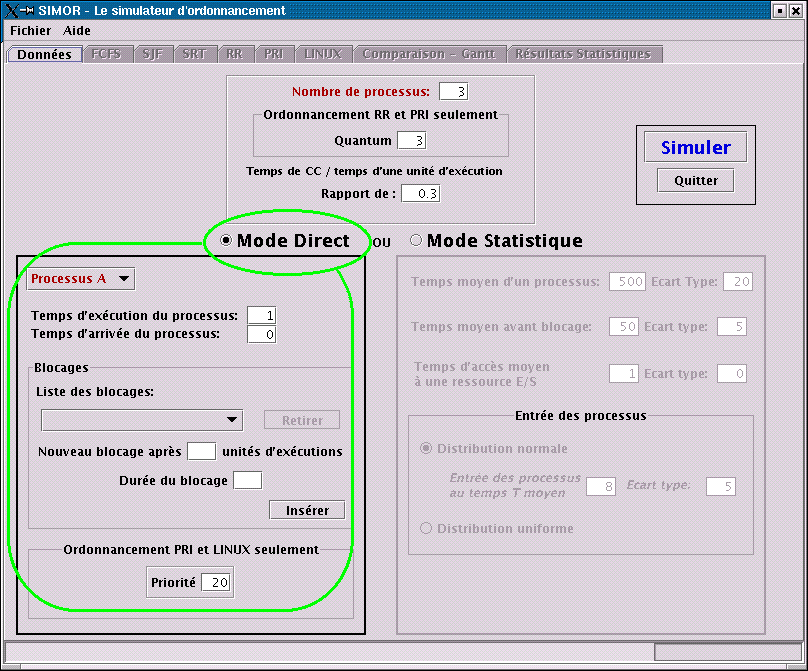
Choix du processus : Tous les processus sont indépendamment
paramétrables. Les champs de données qui suivent le choix du processus
sont directement rattachés à celui-ci. On choisi donc ici le processus à
configurer.
Temps d'exécution du processus : Le nombre d'unités de temps représentant la durée du processus. Ce temps n'inclut pas les temps de blocages.
Temps d'arrivée du processus : Le temps où le processus entre dans la file du processeur.
Liste des blocages : Liste de tous les blocages associés au processus. Les blocages sont désignés par leur temps d'arrivée (après X unités d'exécution du processus) et leur durée. Il est de plus possible de retirer un blocage de la liste en appuyant sur le bouton "Retirer". Pour insérer un nouveau blocage, on inscrit dans les cases prévues le temps d'arrivée du blocage ainsi que sa durée, et on appuie sur "Insérer".
Priorité : La priorité du processus est utile pour les
ordonnancements à priorités pures et Linux. Dans tous les autres cas, la
priorité du processus est simplement ignorée. La priorité du processus
peut varier entre 1 et 40, où 40 est le processus le plus prioritaire.
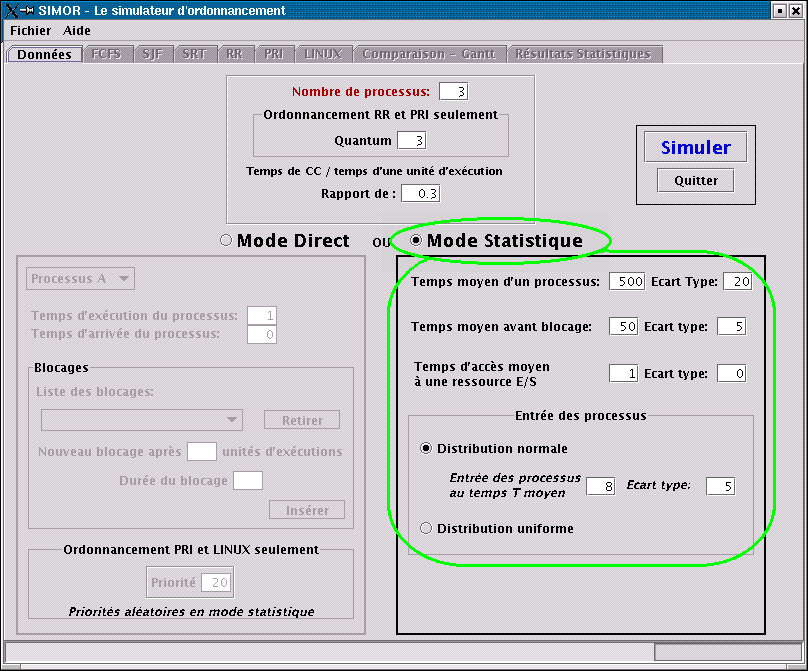
Temps moyen d'un processus : Il s'agit de la durée du processus en
négligeant tous les blocages. Il s'agit donc du nombre moyen de temps
d'exécution qu'un processus nécessite pour s'exécuter au complet. Le
temps moyen est accompagné de l'Écart Type, puisque les temps des
processus sont tirés au hasard selon une distribution uniforme.
Temps moyen avant blocage : C'est
le temps d'exécution moyen nécessaire avant qu'un blocage ne survienne
(requête à une ressource E/S ou tout autre type de blocage). Le temps
moyen est accompagné de l'Écart Type, puisque les temps des
processus sont tirés au hasard selon une distribution uniforme.
Temps d'accès moyen à une ressource E/S
: Le temps d'accès moyen représente la durée moyenne d'un blocage. Le
temps moyen est accompagné de l'Écart Type, puisque les temps des
processus sont tirés au hasard selon une distribution uniforme.
Entrée des processus : L'entrée des
processus représente le temps d'arrivée des processus dans la file du
processeur. Il est possible de faire arriver les processus à des temps
différents selon une distribution uniforme ou normale. Dépendamment de
la distribution choisie, on devra spécifier soit le minimum et le
maximum de la distribution, ou la valeur moyenne et l'écart-type.
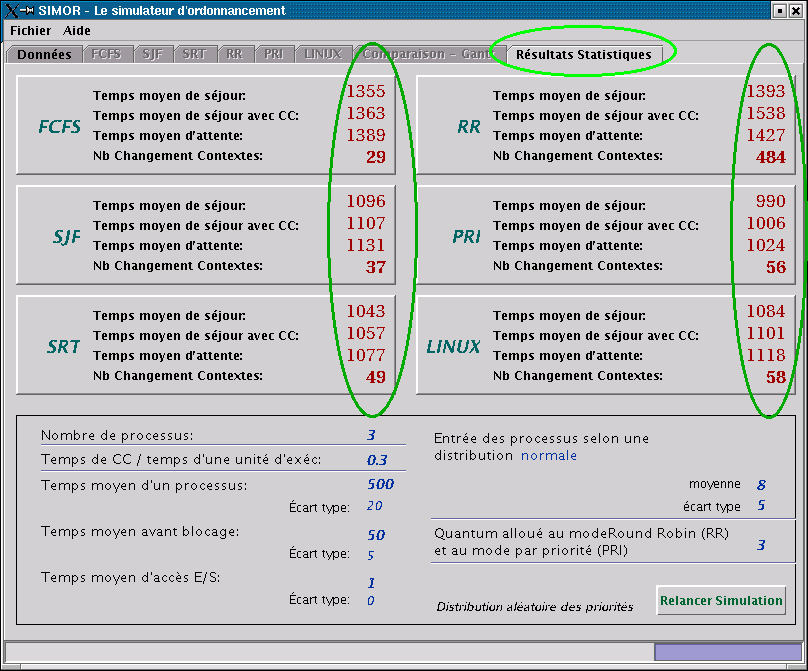
Une fois les informations correctement entrées, la simulation peut être lancée. Lorsque la simulation se termine, les onglets appropriés deviennent automatiquement accessibles pour la lecture des résultats. Les 6 onglets suivant les Données, représentent les résultats obtenus pour chaque type d'ordonnancement supporté par le simulateur (voir les acronymes). L'onglet suivant, Comparaison, est tout simplement un report des diagrammes de Gantt situés sur les onglets précédents pour une meilleure comparaison des séquences d'exécution. Ces informations sont accessibles en mode direct seulement. Le dernier onglet Statistique, est uniquement, et le seul, accessible dans ce mode précis. Il montre la comparaison des temps de séjour et des temps d'accès moyen entre les diverses méthodes dans des situations d'ordre général.
Les résultats obtenus peuvent se trouver sous deux formes
distinctes, dépendamment du type de simulation effectué. Dans le cas
d'une simulation en mode direct, 7 onglets deviennent disponibles une
fois la simulation complétée. Les six premiers de ces onglets
représentent les résultats d'un type précis d'ordonnancement.
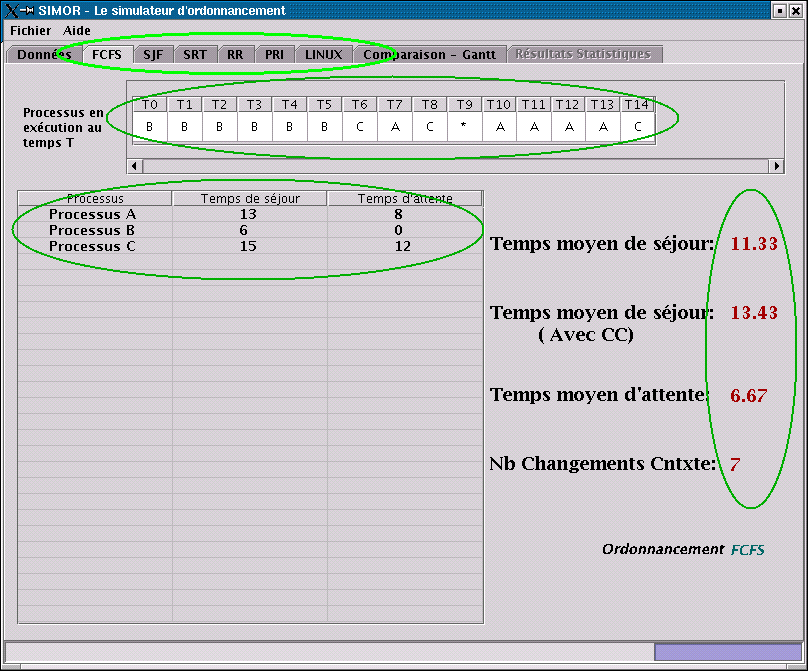
Sur la figure, on voit un exemple de résultats obtenu pour l'algorithme
FCFS. On remarquera :
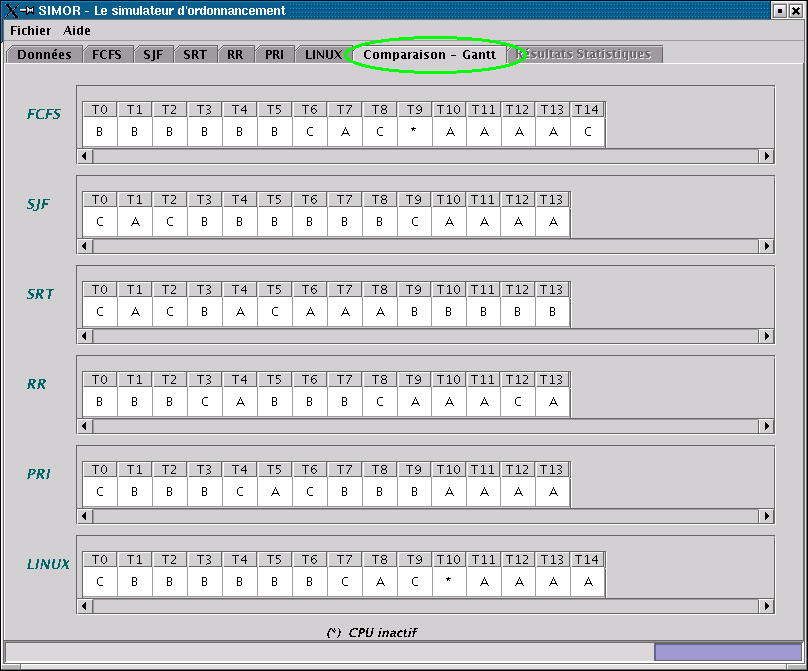
Dans un système d'exploitation réel, un changement de contexte se
produit chaque fois que le processeur bascule d'une tâche à une autre.
L'état inactif du processeur est inexistant : il existe toujours une
tâche Idle qui prend place lorsqu'aucune tâche utile n'est prête
à être exécutée. Ceci implique donc qu'à un instant quelconque où aucun
processus utile ne tourne sur le processeur, si un processus devient
prêt, un changement de contexte doit se faire pour remplacer le
processus Idle. C'est donc dire qu'il y a un changement de
contexte à tout moment lorsque le contenu du processeur change.
Puisque le temps de changement de contexte en en général négligeable
par rapport à une unité d'exécution d'un processus, les changements de
contextes n'apparaissent pas sur le diagramme de Gantt. En effet,
pour représenter les changements de contexte, il aurait fallu avoir des
fractions d'unités de temps! Ceci n'aurait pas apporté beaucoup à la
compréhension, car nous savons maintenant qu'il y a un changement de
contexte pour toute variation dans le processeur.
Au lieu de cela, le nombre de changements de contexte est calculé,
ceci donne une meilleure idée de la fréquence de ceux-ci. De plus, on
peut indiquer un ratio qui établi la relation entre la durée d'un
changement de contexte vis à vis la durée d'une unité d'exécution. De ce
ratio, on peut facilement voir le poids et l'impact d'un trop grand
nombre de ces changements.
L'option d'exportation vers un fichier texte permet à l'usager
d'obtenir un fichier de résultats de la simulation pour consultation
ultérieur. De plus, le format texte est beaucoup plus simple à imprimer
pour les utilisateurs qui préfèrent consulter des documents papier.
Les options d'écriture et de lecture de fichier ne sont offerte
que dans la version autonome (fichier .jar) du simulateur. Cette
limitation est imposée pour des raisons de sécurité par la machine
virtuelle java (celle qui s'occupe d'exécuter les applets java). En
effet, personne n'aimerait qu'un programmeur malveillant s'amuse avec
des fichiers sur son ordinateur via Internet. Pour cette raison, il est
impossible (à moins de conditions particulières) d'effectuer des
écritures et des lectures de fichier via un applet Java. Cette
limitation se fait donc ressentir dans la version "Applet" du simulateur.